Loss Functions in ML
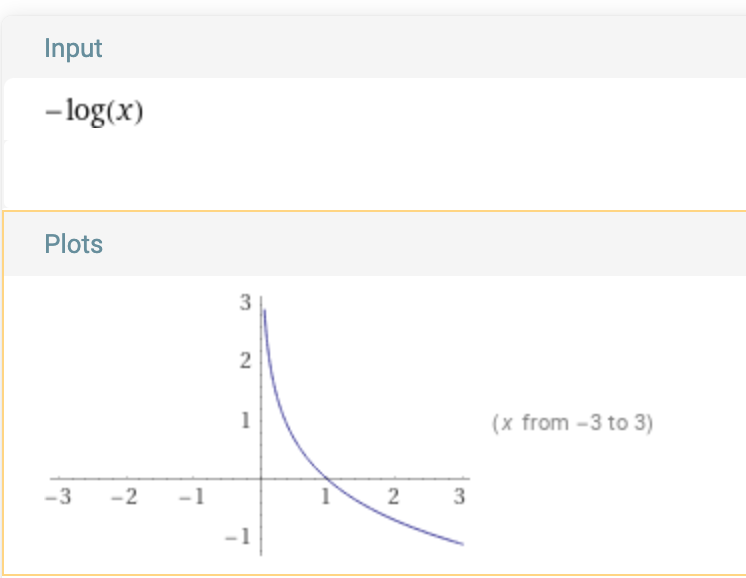
Introduction Loss functions tell the algorithm how far we are from actual truth, and their gradients/derivates help understand how to reduce the overall loss (by changing the parameters being trained on) All losses in keras defined here But why is the loss function expressed as a negative loss? Plot: As probabilities only lie between [0-1], the plot is only relevant between X from 0-1 This means, that it penalises a low probability of success exponentially more....
