
Introduction
In my previous post, I tested a coding LLM on its ability to write React code. Specifically, I tried the currently leading open source model in the HumanEval+ benchmark leaderboard - DeepseekCoder:33b-instruct.
I used this model in development for a few weeks, and published a subset of examples in the post. Even though I tried this on a relatively small problem size, there were some obvious issues that were recognisable to me, namely:-
The randomness problem: LLMs are unable to produce correct code in the first attempt, however a few attempts (sometimes) leads to the correct code output.
The complexity problem: Smaller, more manageable problem with lesser constraints are more feasible, than complex multi-constraint problem.
For example, if I would ask it to code a component and gave both styling and logic constraints in the prompt, it would frequently solve the logic but miss the styling part of the solution.
(Hunch) Out of training problem: I also noticed that it spectacularly fails in smaller sized problems for specific types. For example, while it can write react code pretty well. It’s ability of writing test cases was quite horrid, and will typically just write the test case name, and leave the implementation as a “TODO: Fill this implementation…”.
So I spent some time researching existing literature that could explain the reasoning, and potential solutions to these problems.
How the rest of the post is structured.
HumanEval+ - A summary on this rigorous evaluation of CodeLLMs and how they fair in this extended benchmark. There are some interesting insights and learnings about LLM behavior here.
The effect of Pre-Planning in code LLMs: Insights from this paper on how pre-planning helps produce better code
The effect of using a planning-algorithm (Monte Carlo Tree Search) in the LLM decoding process: Insights from this paper, that suggest using a planning algorithm can improve the probability of producing “correct” code, while also improving efficiency (when compared to traditional beam search / greedy search).
The effect of using a higher-level planning algorithm (like MCTS) to solve more complex problems: Insights from this paper, on using LLMs to make common sense decisions to improve on a traditional MCTS planning algorithm.
Overall - I believe using a combination of these concepts can be viable approach to solving complex coding problems, with higher accuracy than using vanilla implementation of current code LLMs. I’ll detail more insights and summarise the key findings in the end.
Human Eval+
Paper: HumanEval+
Core Problem:
Existing code LLM benchmarks are insufficient, and lead to wrong evaluation of models. The authors found, that by adding new test cases to the HumanEval benchmark, the rankings of some open source LLM’s (Phind, WizardCoder) overshot the scores for ChatGPT (GPT 3.5, not GPT4), which was previously incorrectly ranked higher than the others.
How they create tests cases
Liu et.al augmented the existing HumanEval test suite by
generating some seed inputs by prompting ChatGPT.
Using type-based mutations to generate more test inputs
Comparing the results on these additional inputs on the ground-truth solution to the LLM generated solutions
Adding these new (minimal-set-of) inputs into a new benchmark.
The results
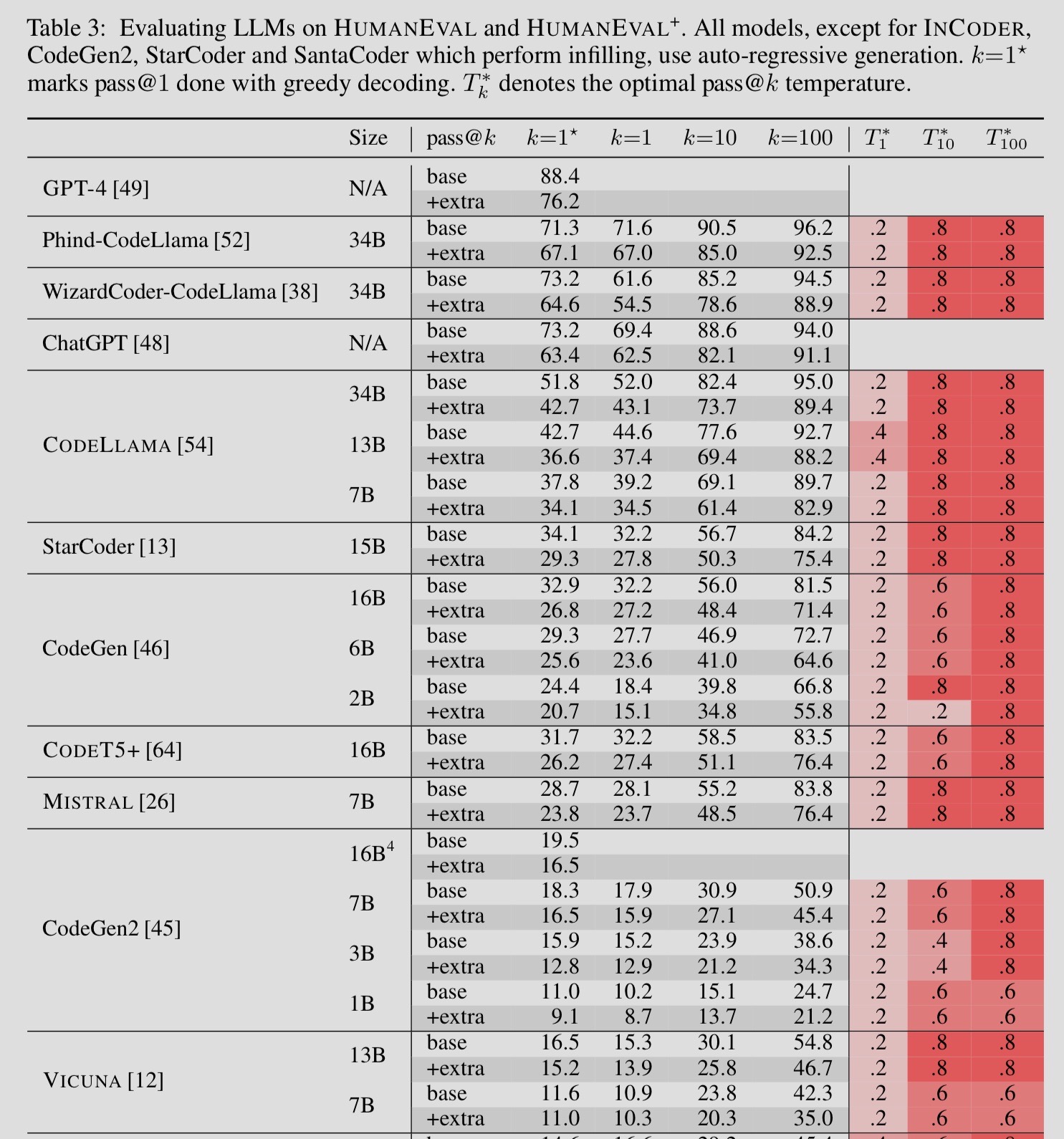
Insights from the paper
1) Increasing K in pass@k , almost always leads to improved benchmark results.
This proves that the correct solution does exist in the solution space of the LLM outputs most of the times, however it may not be the first one that the LLM spits out. Using a strategy that can guide the LLM towards the reward has the potential to lead to better outcomes.
2) Choosing a temperature value
When using a pass@1 (or single greedy output), choose a low temperate of 0.2 or below
For a larger number of passes, a higher temperature value of 0.6 -> 0.8, will lead to good results.
3) Practically, k=10 is a decent default to pick
The improvement between k=1, and k=10 is pretty large. However this improvement, is not really extrapolated in the same degree when moving from k=10, to k=100.
4) New code models are coming up
Comparing the results from the paper, to the current eval board, its clear that the space is rapidly changing and new open source models are gaining traction. (Deepseek-coder wasn’t even present in the original paper)
5) Llama3 is still behind
This one was surprising to me, I thought the 70B LLama3-instruct model, being larger and also trained on 15T tokens, would perform quite well.
However, the benchmark shows its still behind deepseek, wizard and other open source models
Pre-Planning in Code LLMs
Paper: Self-Planning Code Generation with LLM
Core Problem
While chain-of-thought adds some limited reasoning abilities to LLMs, it does not work properly for code-outputs.
Typically, CoT in code is done via creating sequences of comments interspersed with code output.

This is because, while mentally reasoning step-by-step works for problems that mimic human chain of though, coding requires more overall planning than simply step-by-step thinking.
How they solve it
An obvious solution is to make the LLM think about a high level plan first, before it writes the code. This is precisely the subject of evaluation for this paper.
To create such a plan the authors use few-shot learning examples to create plans.
What is a good plan ?
The authors expect the plans to be in a specific fashion.
Namely that it is a number list, and each item is a step that is executable as a subtask.
The plan should always conclude with a return statement.
Results
Adding a self planning step, that adds a high-level plan before the implementation starts-creates a 25% improvement in benchmark results.
Interestingly, the authors also evaluate a multi-turn self planning step, and find it inferior.
In the multi-turn approach, the LM Takes iterative turns to create a final code output as opposed to producing the output in one-turn.
This seems counter-intuitive to me, given all the recent progress in Agentic LLMs.
They offer some clues:-
They find that the multi turn approach does not work as well as a one-shot approach because:-
This can be ascribed to two possible causes: 1) there is a lack of one-to-one correspondence between the code snippets and steps, with the implementation of a solution step possibly interspersed with multiple code snippets; 2) LLM faces challenges in determining the termination point for code generation with a sub-plan. Since the final goal or intent is specified at the outset, this often results in the model persistently generating the entire code without considering the indicated end of a step, making it difficult to determine where to truncate the code. When implemented as a one-phase process, the self-planning approach has been shown to yield slightly improved performance compared to the two-phase way.
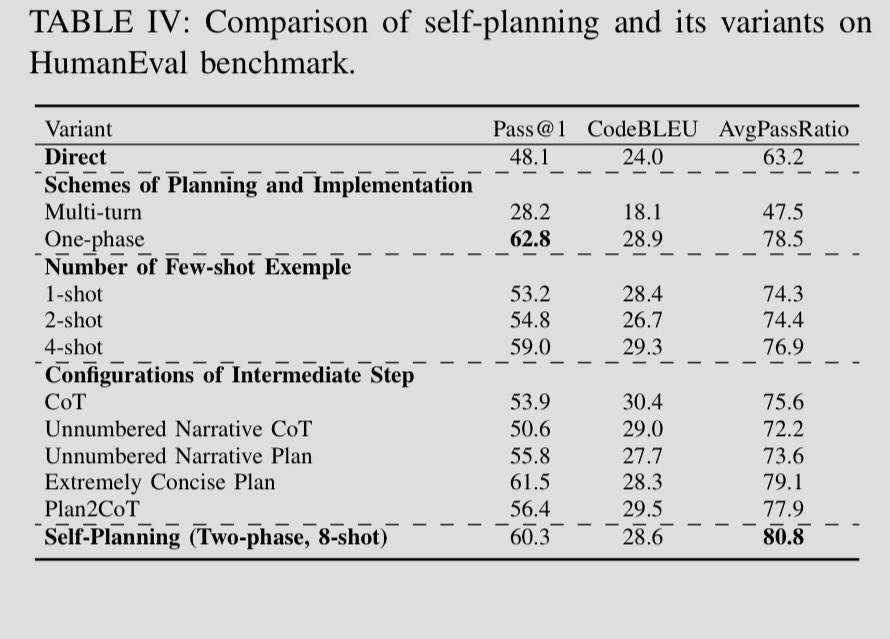
Insights and recommendations from the paper
Considering limited LLM context windows.
The authors suggest a 2-phase plan + 8 shot examples approach produces best results
(2 phase in this context, does not mean 2 turns. It simply means, the LLM is prompted to prepare the plan first, and then the plan is concatenated to produce the final output)
we generally recommend using either 8-shot or 4-shot for self-planning in LLMs.
Planning algorithms in LLM Decoder
Paper: Planning with LLM for code gen
Problem
LLMs being probabilistic machines, they do not always create correct programs in a single run. However, if we sample the code outputs from an LLM enough times, usually the correct program lies somewhere in the sample set. The task of finding the correct output by sampling and filtering is costly. Intuitively, in sampling + filtering, we are not making use of any objectives to focus the search on the “correct” outputs, but merely hoping that the correct output lies somewhere in a large sample.
Can we integrate a planning algorithm with a pre-trained code generation Transformer, achieving an algorithm that generates better programs than the conventional Transformer generation algorithms and the well-accepted sampling + filtering scheme in the literature?
Core Idea
The core idea here is that we can search for optimal code outputs from a transformer effectively by integrating a planning algorithm, like Monte Carlo tree search, into the decoding process as compared to a standard beam search algorithm that is typically used.
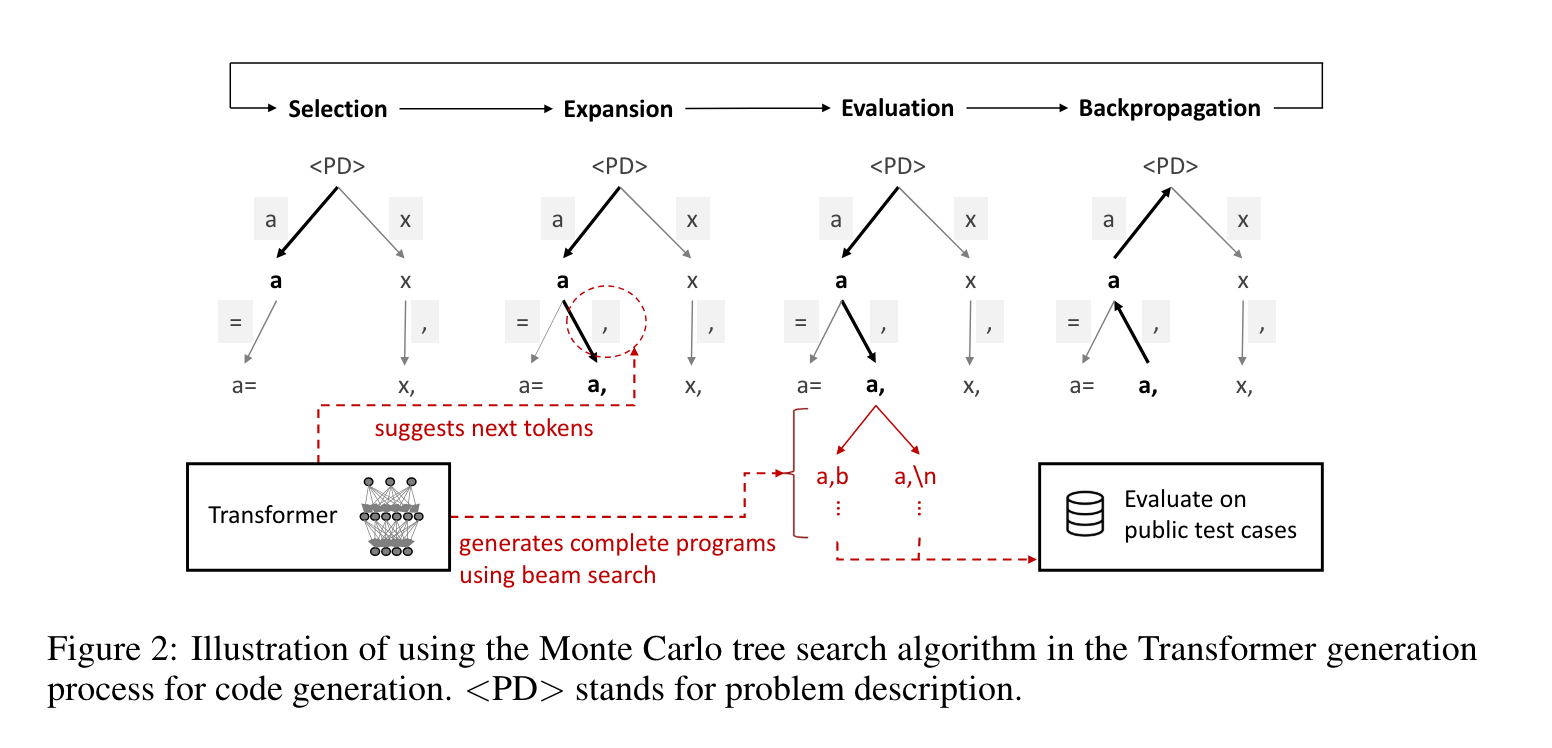
Catch
For this to work, we need to create a reward function with which to evaluate different code outputs produced during the search of each branch in the solution space. The reward function here is based on evaluating test-cases. So an explicit need for “testable” code is required for this approach to work.
But assuming we can create tests, by providing such an explicit reward - we can focus the tree search on finding higher pass-rate code outputs, instead of the typical beam search of finding high token probability code outputs.
Intuitively, transformers are built to produce outputs that match previously seen completions - which may not be the same as a program that is correct and solves the overall problem.
The paper shows, that using a planning algorithm like MCTS can not only create better quality code outputs. But it is also more resource efficient as we do not have to create a large amount of samples to use for filtering.
To achieve this efficiency, a caching mechanism is implemented, that ensures the intermediate results of beam search and the planning MCTS do not compute the same output sequence multiple times.
Another interesting idea, is to use these planner-guided solutions to fine-tune the LLM to improve its future outputs
LLM reasoning for MCTS
Paper: LLM-MCTS - Zhao et.al
The Question
The core concept of this paper intrigues me. In essence, the paper tries to answer the question - “Can the reasoning abilities of LLM models, be used to guide a Monte Carlo search in finding the optimal answer to a higher-level problem like object rearrangement in household"
The 3 options
The authors conduct comparison between 3 solutions
A pure LLM solution (LLM-Policy)
A planner guided solution called LLM-model (LLM guided MCTS), and
A hybrid approach (LLM-MCTS) where the LLMs reasoning is not used as a hard action, but used as part of a heuristic to continue the search process.
How it works
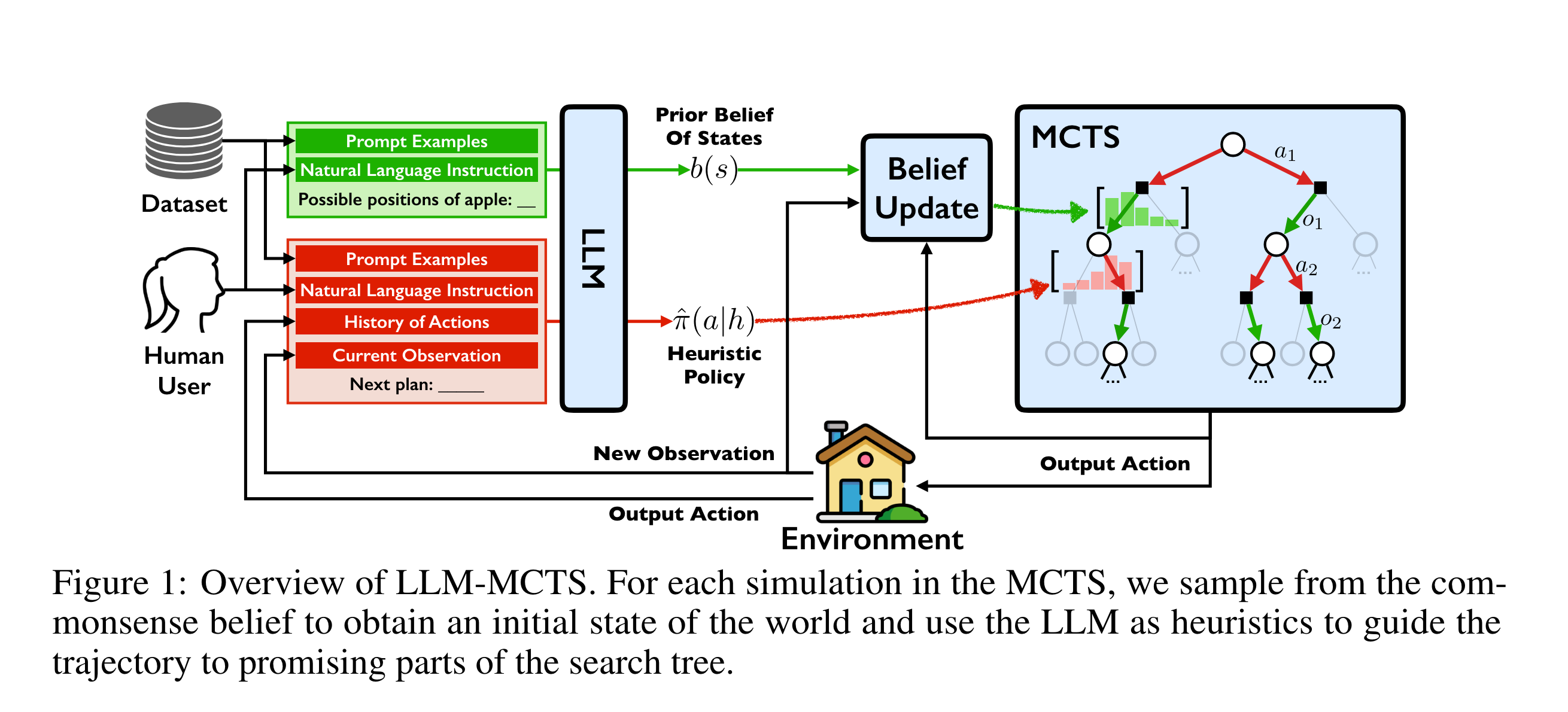
Insights from the paper
1. LLM-MCTS outperforms both the LLM-policy, and LLM-model

2. The improvement is much more noticeable when the problem is Complicated / Novel as opposed to simple.
This quantifies the initial intuition of this post, that LLM’s are unable to solve more complex/novel problems but perform much better for smaller/simpler problems
An intuitive understanding of this, is best explained by the authors via an analogy to the multiplication example. i.e: Multiplying large numbers is hard, but using a algorithm that works on top of foundational concepts becomes a simpler solve.
A decimal number is described as a sequence of n digits,(dn−1, dn−2, . . . , d0). There are two methods of implementing multiplication with an LLM. The first one corresponds to L-Policy. We represent the multiplication function as a table. Each row or column corresponds to a number. The table entry is the multiplication of two numbers, obtained by querying an LLM. Experimentally, GPT4 performs single-digit multiplication perfectly with 100% accuracy, 2-digit multiplication with 99% accuracy, 4-digit multiplication with merely 4% accuracy, and fails almost completely on 5-digit multiplication [ 10 ]. The second approach uses LLM-derived small single-digit multiplication tables, which GPT4 performs with 100% accuracy. To multiply multi-digit numbers, it applies the long multiplication algorithm with the single-digit table. This method corresponds to L-Model. While long multiplication differs from planning in algorithmic details, it plays the same role in L-Model and is highly efficient. Clearly, this second method achieves100% accuracy for arbitrarily large numbers, provided that the single-digit multiplication table is accurate. So, the L-Model outperforms L-Policy for the multiplication task, contrary to the finding for object rearrangement tasks
My take
In scenarios where the problem is complex, it’s solution space is large, AND there exist some known planning algorithms that can solve the larger problem at play - its beneficial to let the planning algorithms take control of the overall process, but let the LLM guide the intelligent search process to utilise its inherent common sense and reasoning abilities.
In essence, when the problem becomes sufficiently complicated and large, it is hard for LLMs to solve the entire problem in one go. This is because, LLMs can’t stop, rethink and evaluate before they answer and lack any second-order thinking. Also, in complicated situations like path finding, a certain level of trial and error search is required to find the answer.
Summarising some key points
LLM’s can solve simpler problems well, but struggle with complex/novel problems
Finding ways to break a complicated problem into smaller pieces, and using known algorithms to combine the pieces is a viable idea.
Tests can be used to focus the LLM decoding process to optimise for correctness without fine-tuning.
In problem spaces where we can use tests to judge program correctness (eg: Test cases, Visual comparison, comparison with ground-truth solutions), we can guide the LLM outputs towards correctness more efficiently.
Further, a planner-guided LLM output can be used to fine-tune the base model to improve its base accuracy
Pre-Planning and Chain-of-thought are cost-effective default solutions to try
It is intuitive, that making these models build a plan and working through the solutions step-by-step would increase correctness, without increasing computation cost much, and as such should probably be defaulted into most developer workflows.
Conclusion
There are some promising ideas in the field of planner-augmented problem solving that can be applied to code generation.
Rigorous study and evaluation is needed to confirm these ideas, and conduct further research.
If there are other papers related to the same field, or you have some insights, I’d would love to know more. Please reach out, or comment to share them with me.