
Introduction
The goal of this series of posts, is to form foundational knowledge that helps us understanding modern state-of-the-art LLM models, and gain a comprehensive understanding of GPT via reading the seminal papers themselves.
In my previous post, I covered transformers via the original paper “Attention is all you need” that brought the innovation that made all this progress possible.
This post will focus on GPT-3 and its predecessors GPT-1 and 2. The progression from GPT 1,2 and finally to 3, explains how the authors found a way to generalise the transformer architecture to task-agnostic workloads, and what led to the discovery of the GPT-3 175B parameter model.
I intend for this to be summary of the original papers, and do refer to the detailed results sections in the paper itself
Papers previously covered
- Previously Covered Transformers, following Vaswani et al. 2017 Google Attention is all you need
Papers covered in this post
GPT-1, following Radford et al. 2018 Improving Language Understanding by Generative Pre-Training
GPT-2, following Radford et al. 2018 Language Models are Unsupervised Multitask Learners
GPT-3: Few shot learners, 2020 OpenAI Language Models are Few-Shot Learners
GPT-1 & 2
While transformers found an effective way to utilise raw textual content to solve tasks like machine translation, there was still no consensus on the most effective way to transfer these learned representations to any other target task.
Existing techniques involved a combination of task-specific model architectures, or using intricate learning schemes.
GPT-1 paper, explores a semi-supervised approach for language understanding tasks using a combination of unsupervised pre-training and a supervised fine-training.
The primary goal, is to find a universal representation that transfers with little adaptation to a wide range of tasks.
Pre-training
The pre-training phase is quite similar to what we previously covered in the transformers paper
The difference, being that the authors use a decoder only architecture (as there is no translation involved here, only predicting the next token)
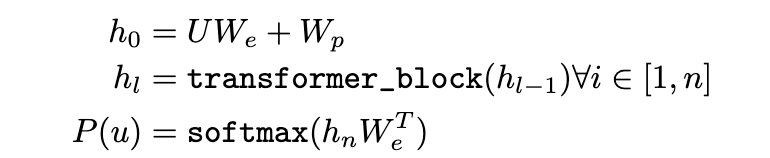
Fine Tuning
This is also quite similar to the previous stage, with some key differences.
The core motivation is, that instead of predicting the next token, the model is supposed to predict the output Y.
So, a pre-labeled dataset C is chosen, where given the input in the form of tokens X_1 … X_n, the model is evaluated to predict y
To do this, an additional linear output layer with parameters W_y is used to predict the final y
Auxilary objectives
Additionally, they add an auxiliary objective (language modelling), to the mix, as this helps with generalisation.
To do this, they combine the Loss functions of the pre-training with the auxiliary task
Task Specific Input Transformations
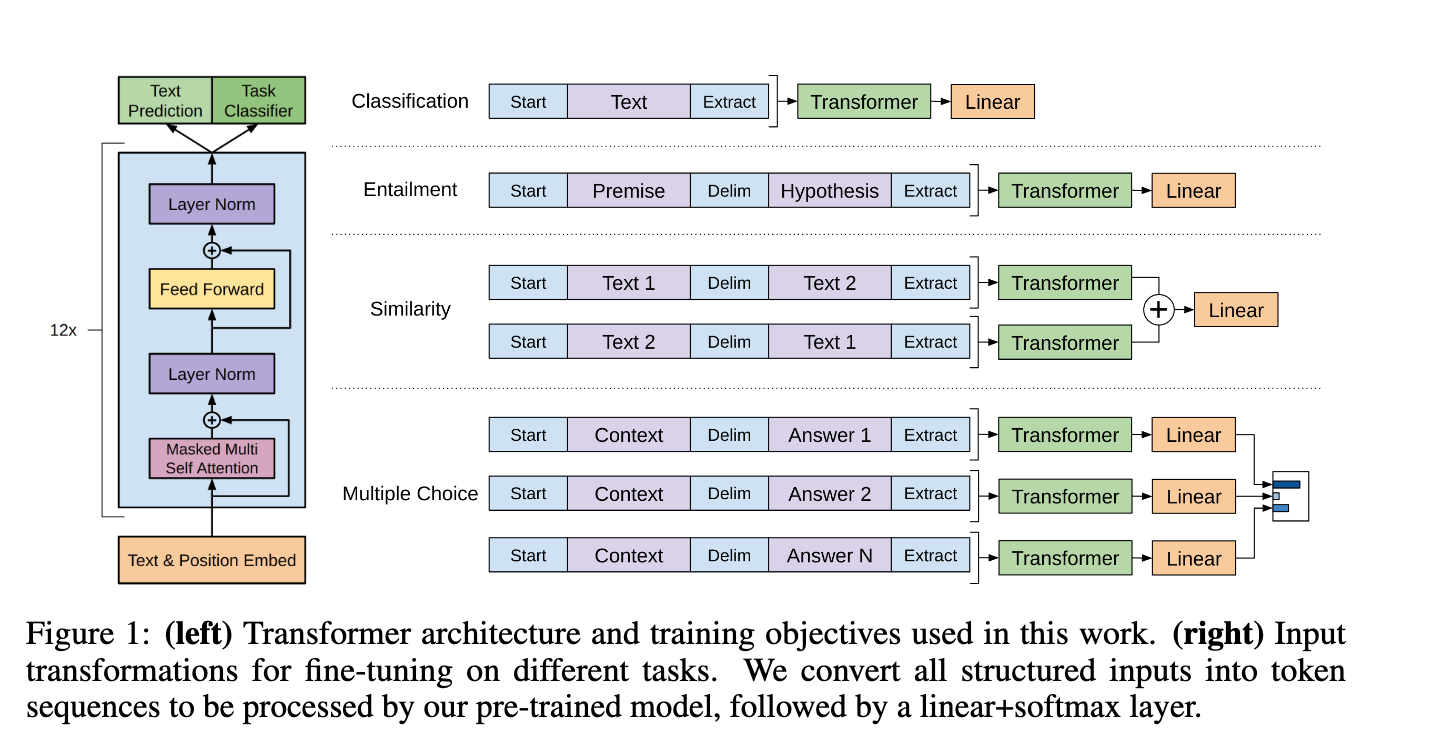
As described from the paper, with some modifications to the input they are able to use the same model for different tasks.
we convert structured inputs into an ordered sequence that our pre-trained model can process.
To explain with an example, consider how they change the inputs for sentence similarity tasks
For similarity tasks, there is no inherent ordering of the two sentences being compared. To reflect this, we modify the input sequence to contain both possible sentence orderings (with a delimiter in between) and process each independently to produce two sequence representations hm l which are added element-wise before being fed into the linear output layer
GPT-2
Primarily it is a larger model (1.5B) with a few additional modificaitons
Layer normalization (Ba et al., 2016) was moved to the input of each sub-block, similar to a pre-activation residual network (He et al., 2016) and an additional layer normalization was added after the final selfattention block. A modified initialization which accounts for the accumulation on the residual path with model depth is used. We scale the weights of residual layers at initialization by a factor of 1/√N where N is the number of residual layers.
The vocabulary is expanded to 50,257. We also increase the context size from 512 to 1024 tokens and a larger batchsize of 512 is used
GPT-3 - Language Models are Few-Shot Learners
The motivation
A major limitation to this approach is that while the architecture (GPT-1/2) is task-agnostic, there is still a need for task-specific datasets and task-specific fine-tuning: to achieve strong performance on a desired task typically requires fine-tuning on a dataset of thousands to hundreds of thousands of examples specific to that task. Removing this limitation would be desirable, for several reasons
Humans do not require large supervised datasets to learn most language tasks – a brief directive in natural language (e.g. “please tell me if this sentence describes something happy or something sad”) or at most a tiny number of demonstrations (e.g. “here are two examples of people acting brave; please give a third example of bravery”) is often enough to produce satisfactory results.
Can machines learn like humans do ? With few-shots ?
What if we give few examples to the model, to come with the answer like humans learn. Will that work?
“In-context learning”, uses the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
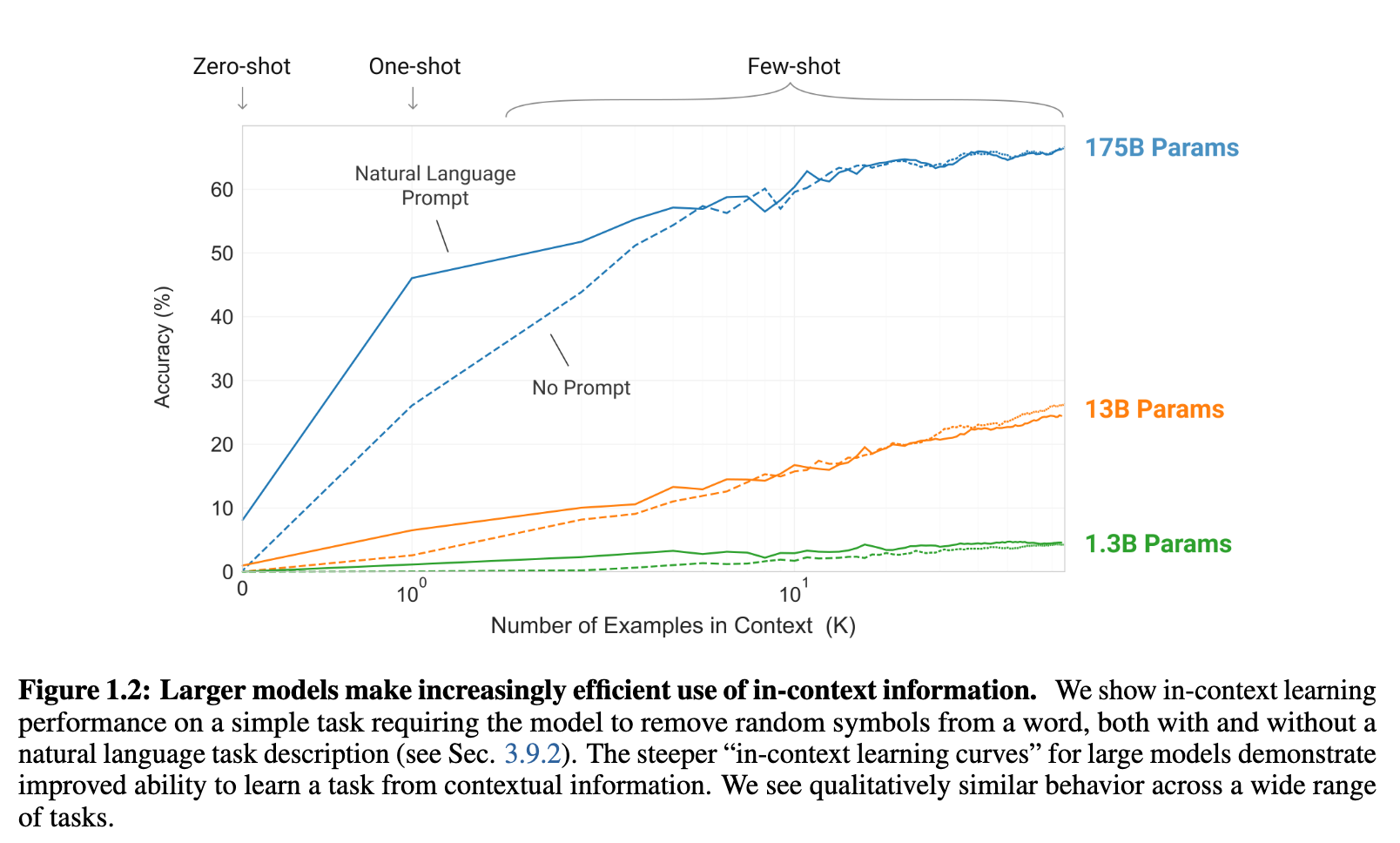
While initially, the results were not at par with the fine-tuning approach. The authors believed there is hope, as they see a linear trend of improvement with increased model sizes. The authors hence hope that increased model size, would also help with the “in-context” learning capabilities, to bring them at par.
Since in-context learning involves absorbing many skills and tasks within the parameters of the model, it is plausible that in-context learning abilities might show similarly strong gains with scale
To test this, the authors built a 175B parameters model, and measured its in-context learning abilities.
They test in the following conditions
(a) “few-shot learning”, or in-context learning where we allow as many demonstrations as will fit into the model’s context window (typically 10 to 100), (b) “one-shot learning”, where we allow only one demonstration, and (c) “zero-shot” learning, where no demonstrations are allowed and only an instruction in natural language is given to the model. GPT-3 could also in principle be evaluated in the traditionalfine-tuning setting, but we leave this to future work

Model architecture
We use the same model and architecture as GPT-2 [ RWC+19 ], including the modified initialization, pre-normalization, and reversible tokenization described therein, with the exception that we use alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar to the Sparse Transformer [ CGRS19 ].
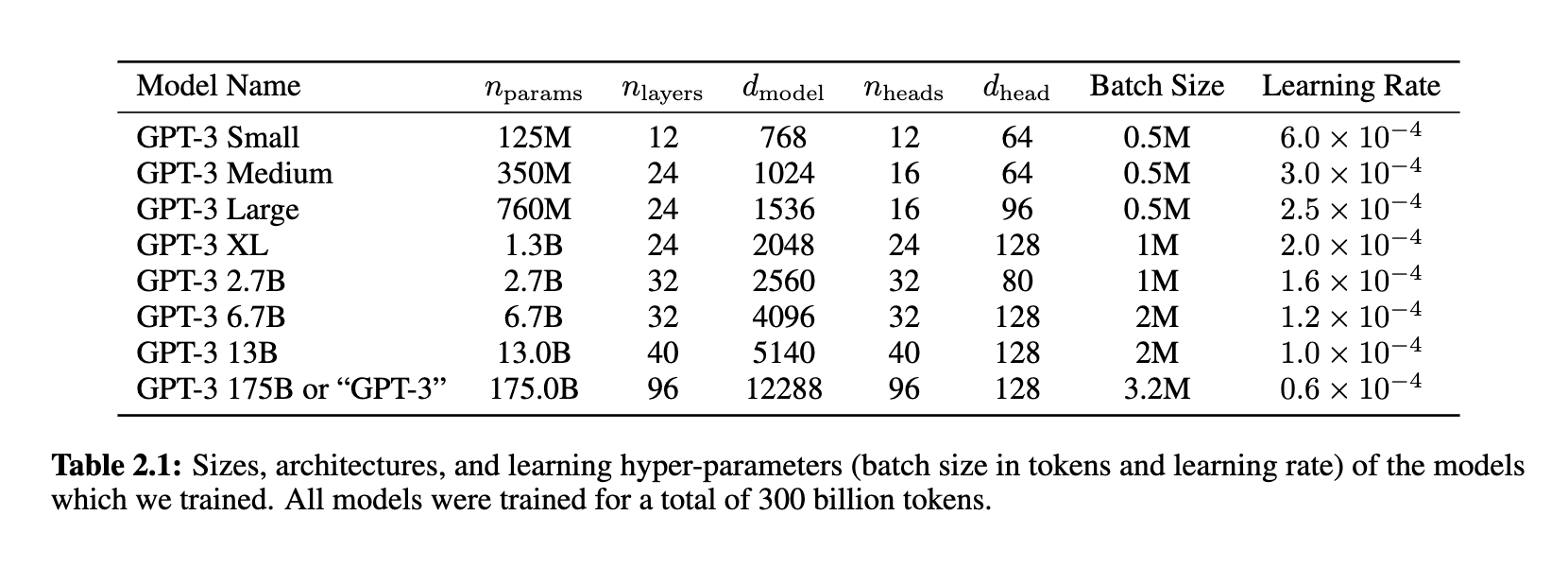
Results
The authors then show a variety of results on various tasks like news article generation, story closure, Translation, Common sense reasoning, Reading comprehension. The results are fascinating, and are best read from the paper directly than me repeating them here.
Conclusion
The success of ChatGPT is something we see now, but clearly it was years in the making and required ruthless process of discovery and experimentaion.
My personal takeaways are
The authors formulated a varied set of “tests” along with a large pool of training data. They evaluated the output across translation, comprehension, question answering etc.
The authors followed a clear hypothesis, tests, result method - and for the most part tested a limited set of parameters in each test. In the GPT-3 example, they are majorly testing size of the model compared with performance.
The ability to question ones own achievements. Even though they achieved great results from their GPT 1 and 2 models, they found issues in the fine-tuning approach and were able to pivot.
I’m next interested in, models that take visual inputs, and how the world is reaching GPT-4V (visual) multi-modal techniques.