Introduction
The goal of this post is to deep-dive into LLM’s that are specialised in code generation tasks, and see if we can use them to write code.
Note: Unlike copilot, we’ll focus on locally running LLM’s. This should be appealing to any developers working in enterprises that have data privacy and sharing concerns, but still want to improve their developer productivity with locally running models.
To test our understanding, we’ll perform a few simple coding tasks, and compare the various methods in achieving the desired results and also show the shortcomings.
The goal - A few simple coding task
Test 1: Generate a higher-order-component / decorator that enables logging on a react component
Test 2: Write a test plan, and implement the test cases
Test 3: Parse an uploaded excel file in the browser.
How the rest of the post is structured
We’re going to cover some theory, explain how to setup a locally running LLM model, and then finally conclude with the test results.
Part 1: Quick theory
Instead of explaining the concepts in painful detail, I’ll refer to papers and quote specific interesting points that provide a summary. For a detailed reading, refer to the papers and links I’ve attached.
Instruction Fine-tuning: Why instruction fine-tuning leads to much smaller models that can perform quite well on specific tasks, compared to much larger models
Open source models available: A quick intro on mistral, and deepseek-coder and their comparison.
Model Quantization: How we can significantly improve model inference costs, by improving memory footprint via using less precision weights.
If you know all of the above, you may want to skip to Part 2
Part 2: Local LLM Setup
Using Ollama and setting up my VSCode extension
VSCode Extension available here: https://github.com/Kshitij-Banerjee/kb-ollama-coder
Part 3: Test Results
Showing results on all 3 tasks outlines above.
[Part 1] Understanding Instruction Finetuning
Before we venture into our evaluation of coding efficient LLMs. Let’s quickly discuss what “Instruction Fine-tuning” really means.
We refer to this paper: Training language models to follow instructions with human feedback
Why instruction fine-tuning ?
predicting the next token on a webpage from the internet—is different from the objective “follow the user’s instructions helpfully and safely”
Performance Implications
In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer paramete
How they did it?
Specifically, we use reinforcement learning from human feedback (RLHF; Christiano et al., 2017; Stiennon et al., 2020) to fine-tune GPT-3 to follow a broad class of written instructions. This technique uses human preferences as a reward signal to fine-tune our models. We first hire a team of 40 contractors to label our data, based on their performance on a screening tes We then collect a dataset of human-written demonstrations of the desired output behavior on (mostly English) prompts submitted to the OpenAI API3 and some labeler-written prompts, and use this to train our supervised learning baselines. Next, we collect a dataset of human-labeled comparisons between outputs from our models on a larger set of API prompts. We then train a reward model (RM) on this dataset to predict which model output our labelers would prefer. Finally, we use this RM as a reward function and fine-tune our supervised learning baseline to maximize this reward using the PPO algorithm
Paper Results
We call the resulting models InstructGPT.
{:height 636, :width 1038}
On the TruthfulQA benchmark, InstructGPT generates truthful and informative answers about twice as often as GPT-3 During RLHF fine-tuning, we observe performance regressions compared to GPT-3 We can greatly reduce the performance regressions on these datasets by mixing PPO updates with updates that increase the log likelihood of the pretraining distribution (PPO-ptx), without compromising labeler preference scores. InstructGPT still makes simple mistakes. For example, InstructGPT can still fail to follow instructions, make up facts, give long hedging answers to simple questions, or fail to detect instructions with false premises$$
Some notes on RLHF
Step 1: Supervised Fine Tuning:
We fine-tune GPT-3 on our labeler demonstrations using supervised learning. We trained for 16 epochs, using a cosine learning rate decay, and residual dropout of 0.2
Step 2 : Reward model
Starting from the SFT model with the final unembedding layer removed, we trained a model to take in a prompt and response, and output a scalar reward The underlying goal is to get a model or system that takes in a sequence of text, and returns a scalar reward which should numerically represent the human preference. These reward models are themselves pretty huge. 6B parameters in Open AI case
Step 3: Fine-tuning with RL using PPO
PPO : Proximal Policy Optimization
Given the prompt and response, it produces a reward determined by the reward model and ends the episode. In addition, we add a per-token KL penalty from the SFT model at each token to mitigate overoptimization of the reward model. The value function is initialized from the RM. We call these models “PPO.”
From : https://huggingface.co/blog/rlhf
“Let’s first formulate this fine-tuning task as a RL problem. First, the policy is a language model that takes in a prompt and returns a sequence of text (or just probability distributions over text). The action space of this policy is all the tokens corresponding to the vocabulary of the language model (often on the order of 50k tokens) and the observation space is the distribution of possible input token sequences, which is also quite large given previous uses of RL (the dimension is approximately the size of vocabulary ^ length of the input token sequence). The reward function is a combination of the preference model and a constraint on policy shift.” Concatenated with the original prompt, that text is passed to the preference model, which returns a scalar notion of “preferability”, rθ. In addition, per-token probability distributions from the RL policy are compared to the ones from the initial model to compute a penalty on the difference between them. In multiple papers from OpenAI, Anthropic, and DeepMind, this penalty has been designed as a scaled version of the Kullback–Leibler (KL) divergence between these sequences of distributions over tokens, r_kl. The KL divergence term penalizes the RL policy from moving substantially away from the initial pretrained model with each training batch, which can be useful to make sure the model outputs reasonably coherent text snippets. Finally, the update rule is the parameter update from PPO that maximizes the reward metrics in the current batch of data (PPO is on-policy, which means the parameters are only updated with the current batch of prompt-generation pairs). PPO is a trust region optimization algorithm that uses constraints on the gradient to ensure the update step does not destabilize the learning process.
Helpful schematic showing the RL fine-tune process

Final Thoughts
InstructGPT outputs are more appropriate in the context of a customer assistant, more often follow explicit constraints defined in the instruction (e.g. “Write your answer in 2 paragraphs or less.”),
Are less likely to fail to follow the correct instruction entirely,
Are less likely to make up facts (‘hallucinate’) less often in closed-domain tasks. These results suggest that InstructGPT models are more reliable and easier to control than GPT-3
Comparison of GPT vs Instruct GPT

[Part 1] Deep dive into Mistral Models
Brief introduction to Mistral models, their architecture, and key features
We refer to the paper: Mistral 7b
Objective:
The search for balanced models delivering both high-level performance and efficiency
Key Results:
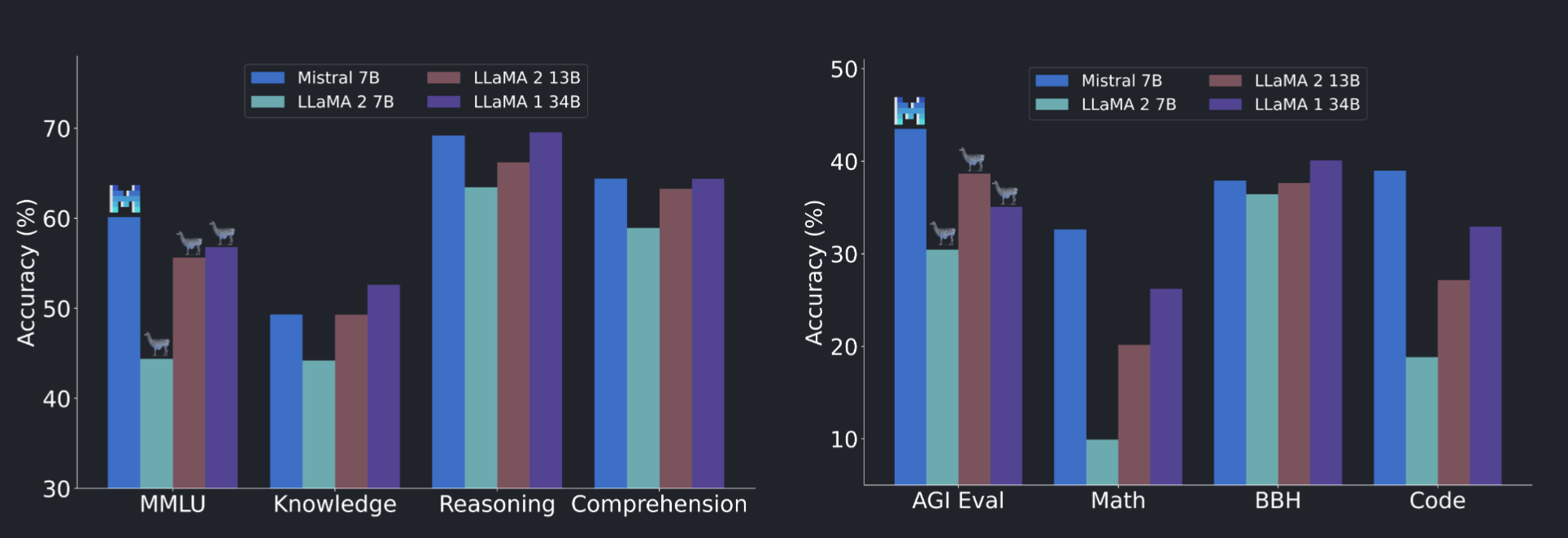
Mistral 7B outperforms the previous best 13B model (Llama 2, [ 26]) across all tested benchmarks, and surpasses the best 34B model (LLaMa 34B, [ 25 ]) in mathematics and code generation. Furthermore, Mistral 7B approaches the coding performance of Code-Llama 7B [ 20 ], without sacrificing performance on non-code related benchmarks
Key Insights:
Mistral 7B leverages grouped-query attention (GQA) [ 1 ], and sliding window attention (SWA) [6, 3]. GQA significantly accelerates the inference speed, and also reduces the memory requirement during decoding, allowing for higher batch sizes hence higher throughput, a crucial factor for real-time applications. In addition, SWA is designed to handle longer sequences more effectively at a reduced computational cost
Sliding Window Attention
Why?
The number of operations in vanilla attention is quadratic in the sequence length, and the memory increases linearly with the number of tokens. At inference time, this incurs higher latency and smaller throughput due to reduced cache availability. To alleviate this issue, we use sliding window attention: each token can attend to at most W tokens from the previous layer

Note that tokens outside the sliding window still influence next word prediction. At each attention layer, information can move forward by W tokens. Hence, after k attention layers, information can move forward by up to k × W tokens SWA exploits the stacked layers of a transformer to attend information beyond the window size W . The hidden state in position i of the layer k, hi, attends to all hidden states from the previous layer with positions between i − W and i. Recursively, hi can access tokens from the input layer at a distance of up to W × k tokens, as illustrated in Figure 1. At the last layer, using a window size of W = 4096, we have a theoretical attention span of approximately131K tokens. In practice, for a sequence length of 16K and W = 4096, changes made to FlashAttention [ 11 ] and xFormers [18 ] yield a 2x speed improvement over a vanilla attention baseline. This fixed attention span, means we can implement a rolling buffer cache. After W size, the cache starts overwriting the from the beginning. This also allows some pre-filling based optimizations.
Comparison with Llama
Instruction Finetuning
To evaluate the generalization capabilities of Mistral 7B, we fine-tuned it on instruction datasets publicly available on the Hugging Face repository. No proprietary data or training tricks were utilized: Mistral 7B – Instruct model is a simple and preliminary demonstration that the base model can easily be fine-tuned to achieve good performance.
System prompt
We introduce a system prompt (see below) to guide the model to generate answers within specified guardrails, similar to the work done with Llama 2. The prompt: “Always assist with care, respect, and truth. Respond with utmost utility yet securely. Avoid harmful, unethical, prejudiced, or negative content. Ensure replies promote fairness and positivity.”
How to select various model sizes, a Thumbrule from Mistral AI.
Refer to this article: Model Selection
TL;DR
Small Tasks (Custom support, classification) => use Mistral Small
Medium Tasks (Data Extraction, Summarizing Documents, Writing emails.. ) => Mistral medium
Complex Tasks (Code Generation, RAG) => Mistral Large
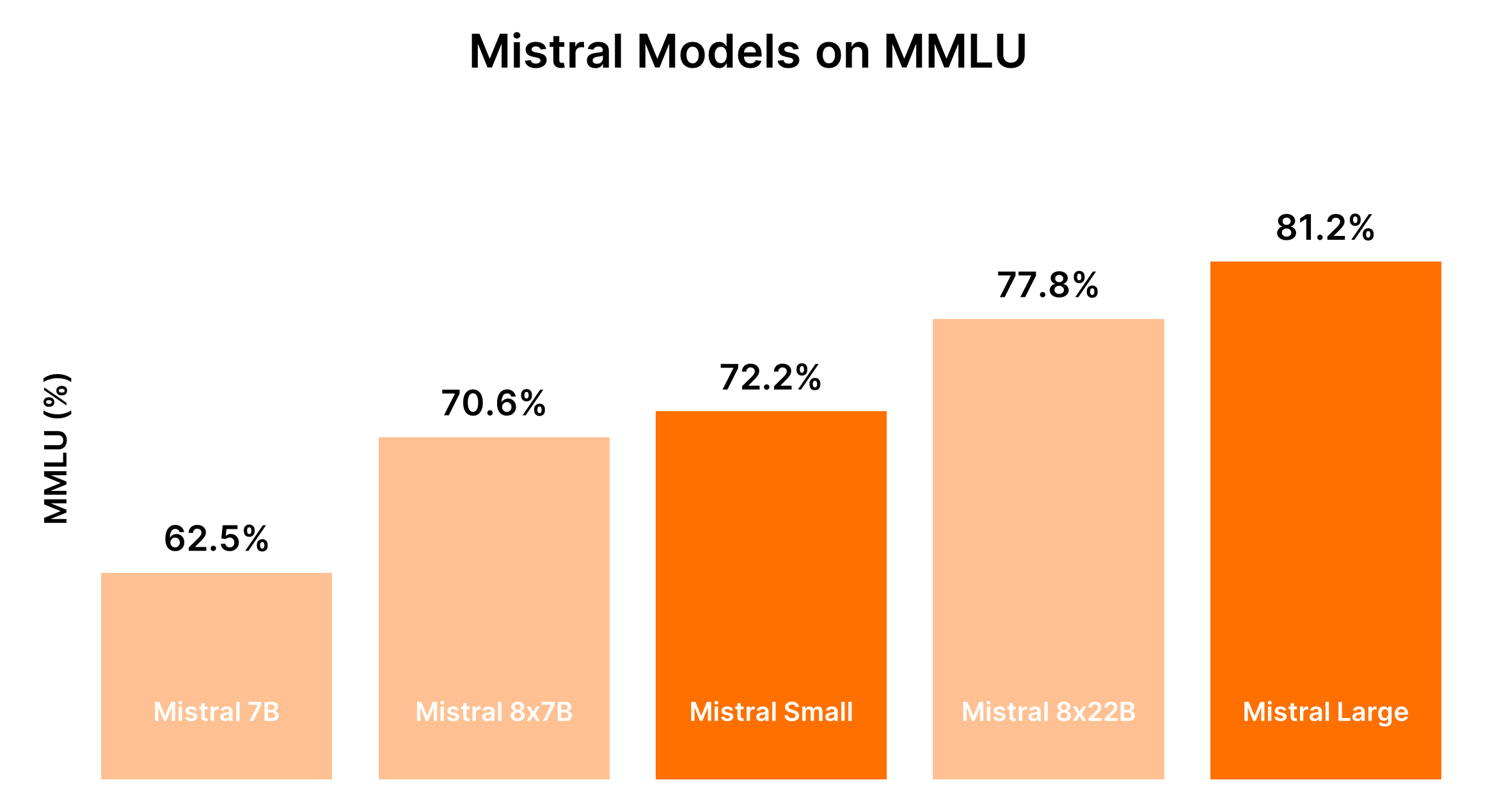
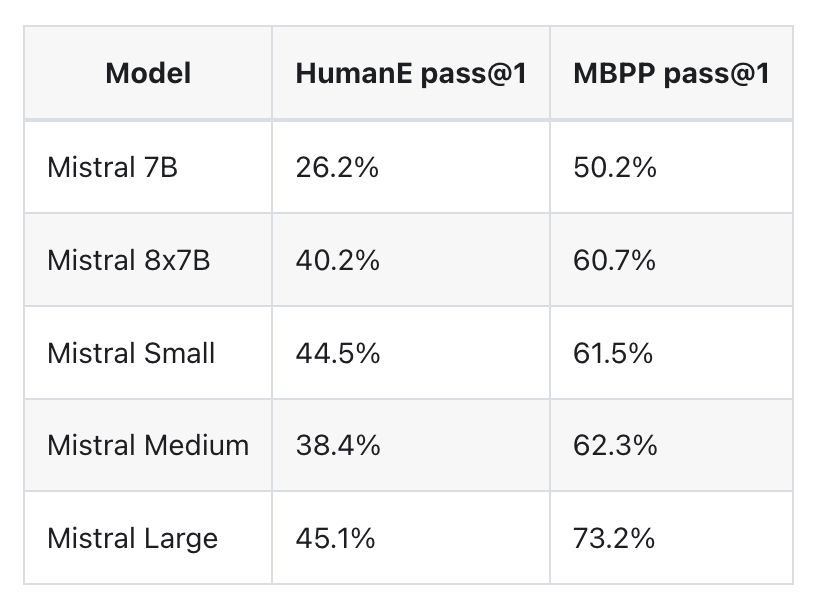
Benchmark on coding :
| Model | MMLU | hellaswag (10-shot) | winograde (5-shot) | arc challenge (25-shot) | TriviaQA (5-shot) | TruthfulQA |
|---|---|---|---|---|---|---|
| Mistral 7B | 62.5% | 83.1% | 78.0% | 78.1% | 68.8% | 42.35% |
| Mixtral 8x7B | 70.6% | 86.7% | 81.2% | 85.8% | 78.38% | 47.5% |
| Mistral Small | 72.2% | 86.9% | 84.7% | 86.9% | 79.5% | 51.7% |
| Mistral Medium | 75.3% | 88.0% | 88% | 89.9% | 81.1% | 47% |
| Mistral Large | 81.2% | 89.2% | 86.7% | 94.0% | 82.7% | 50.6% |
[Part 1] Deepseek Coder, an upgrade?
Overview of Eval metrics
Before we understand and compare deepseeks performance, here’s a quick overview on how models are measured on code specific tasks.
Leaderboard is provided here : https://evalplus.github.io/leaderboard.html
What is HumanEval ?
https://github.com/openai/human-eval
HumanEval consists of 164 hand-written Python problems that are validated using test cases to assess the code generated by a Code LLM in a zero-shot setting,
What is MBPP ?
https://huggingface.co/datasets/mbpp
While the MBPP benchmark includes 500 problems in a few-shot setting.
DS-1000: More practical programming tasks, compared to Human Eval
DS-1000 benchmark, as introduced in the work by Lai et al. (2023), offers a comprehensive collection of 1,000 practical and realistic data science workflows across seven different libraries
Deepseek coder
Summary
Each model in the series has been trained from scratch on 2 trillion tokens sourced from 87 programming languages, ensuring a comprehensive understanding of coding languages and syntax. Refer to the paper from DeepSeek coder: DeepSeek Code
Useful links:
https://deepseekcoder.github.io/
https://ollama.com/library/deepseek-coder/tags
How it’s built
Repository Context in Pre-training
Besides, we attempt to organize the pretraining data at the repository level to enhance the pre-trained model’s understanding capability within the context of cross-files within a repository They do this, by doing a topological sort on the dependent files and appending them into the context window of the LLM. More details below.
We find that it can significantly boost the capability of cross-file code generation
Next token prediction + Fill-in-the middle (like BERT)
In addition to employing the next token prediction loss during pre-training, we have also incorporated the Fill-In-Middle (FIM) approach.
16K context window (Mistral models have 4K sliding window attention)
To meet the requirements of handling longer code inputs, we have extended the context length to 16K. This adjustment allows our models to handle more complex and extensive coding tasks, thereby increasing their versatility and applicability in various coding scenarios
Data Preparation

Filtering Rule:
TL;DR: Remove non-code related, or data heavy files
Remove files with avg line length > 100, OR, maximum line length > 1000 characters.
Remove files with fewer than 25% alphabetic characters
remove <?xml version files
JSON/YAML files - keep fields that have character counts ranging from 50 -> 5000 . This removes data-heavy files.
Dependency Parsing
Instead of simply passing in the current file, the dependent files within repository are parsed.
Parse Dependency between files, then arrange files in order that ensures context of each file is before the code of the current file. By aligning files based on dependencies, it accurately represents real coding practices and structures.
This enhanced alignment not only makes our dataset more relevant but also potentially increases the practicality and applicability of the model in handling project-level code scenarios It’s worth noting that we only consider the invocation relationships between files and use regular expressions to extract them, such as"import" in Python, “using” in C#, and “include” in C. A topological sort algorithm for doing this is provided in the paper.
To incorporate file path information, a comment indicating the file’s path is added at the beginning of each file.
Model Architecture
Each model is a decoder-only Transformer, incorporating Rotary Position Embedding (RoPE) Notably, the DeepSeek 33B model integrates Grouped-Query-Attention (GQA) as described by Su et al. (2023), with a group size of 8, enhancing both training and inference efficiency. Additionally, we employ FlashAttention v2 (Dao, 2023) to expedite the computation involved in the attention mechanism we use AdamW (Loshchilov and Hutter, 2019) as the optimizer with 𝛽1 and 𝛽2 values of 0.9 and 0.95. he learning rate at each stage is scaled down to√︃ 110 of the preceding stage’s rate Context Length:
Theoretically, these modifications enable our model to process up to 64K tokens in context. However, empirical observations suggest that the model delivers its most reliable outputs within a 16K token range.\
Instruction Tuning
This data comprises helpful and impartial human instructions, structured by the Alpaca Instruction format. To demarcate each dialogue turn, we employed a unique delimiter token <|EOT|>
Performance
Surpasses GPT3.5, and within reach of GPT4
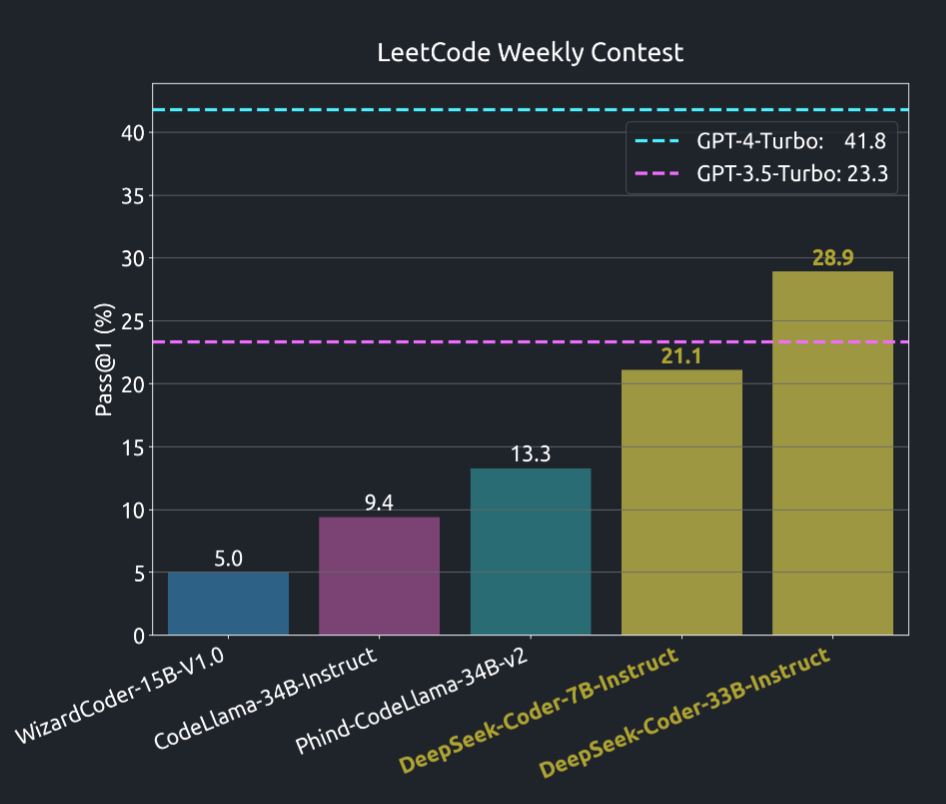
To evaluate the model’s multilingual capabilities, we expanded the Python problems of Humaneval Benchmark to seven additional commonly used programming languages, namely C++, Java, PHP, TypeScript (TS), C#, Bash, and JavaScript (JS) (Cassano et al.,2023). For both benchmarks, We adopted a greedy search approach and re-implemented the baseline results using the same script and environment for fair comparison.
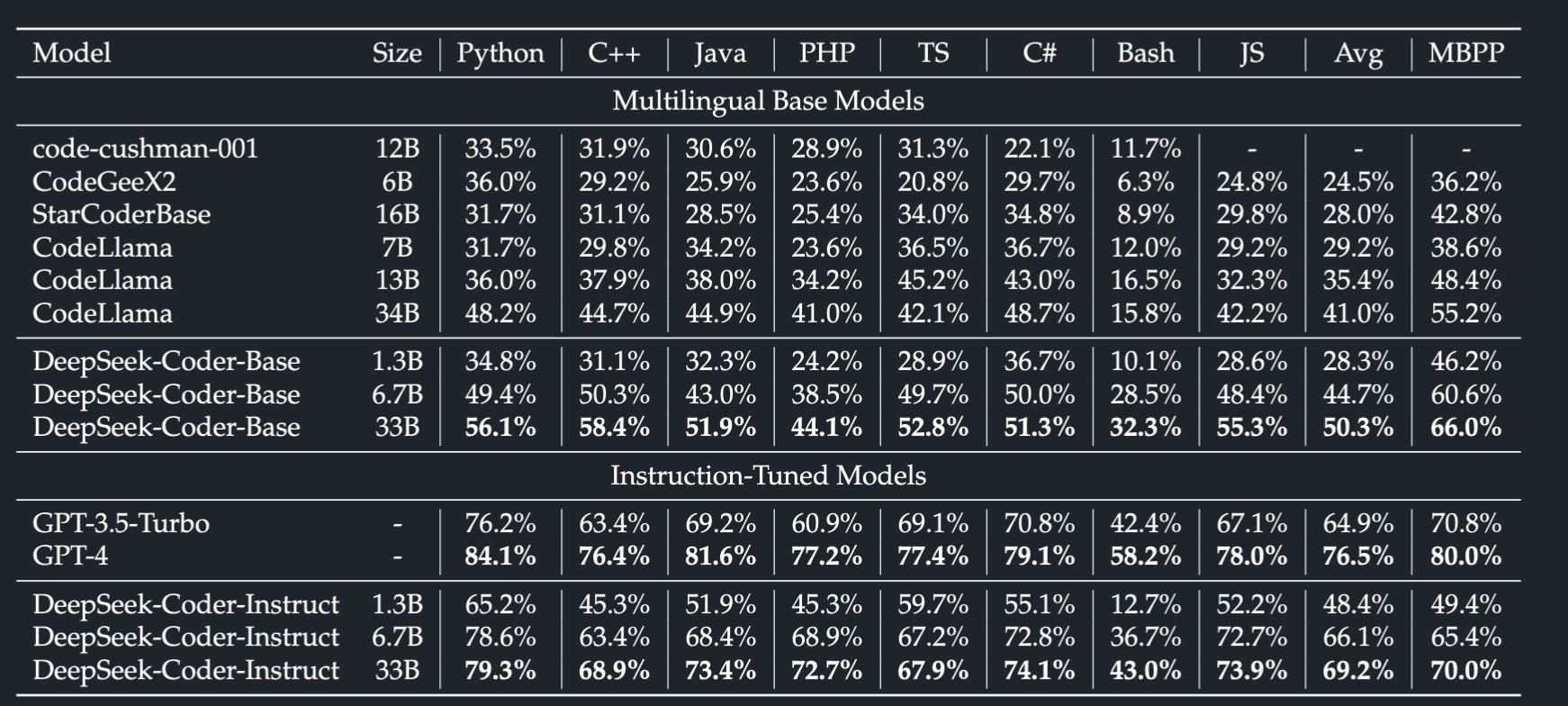
Interesting Notes
Chain of thought prompting
Our analysis indicates that the implementation of Chain-of-Thought (CoT) prompting notably enhances the capabilities of DeepSeek-Coder-Instruct models. This improvement becomes particularly evident in the more challenging subsets of tasks. By adding the directive, “You need first to write a step-by-step outline and then write the code.” following the initial prompt, we have observed enhancements in performance. This observation leads us to believe that the process of first crafting detailed code descriptions assists the model in more effectively understanding and addressing the intricacies of logic and dependencies in coding tasks, particularly those of higher complexity. Therefore, we strongly recommend employing CoT prompting strategies when utilizing DeepSeek-Coder-Instruct models for complex coding challenges.
[Part 1] Model Quantization
Along with instruction fine-tuning, another neat technique that makes LLM’s more performant (in terms of memory and resources), is model quantization
Model quantization enables one to reduce the memory footprint, and improve inference speed - with a tradeoff against the accuracy.
In short, Quantization is a process from moving the weights of the model, from a high-information type like fp32 to a low-information but performant data-type like int8
Reference: Huggingface guide on quantization - https://huggingface.co/docs/optimum/en/concept_guides/quantization
The two most common quantization cases are float32 -> float16 and float32 -> int8.
Some schematics that explain the concept.
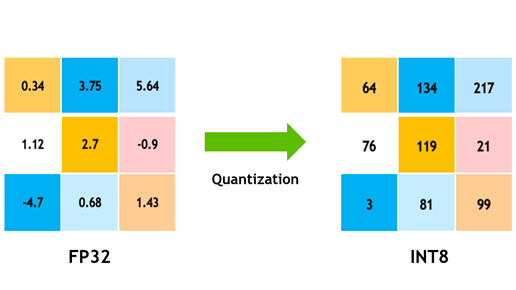
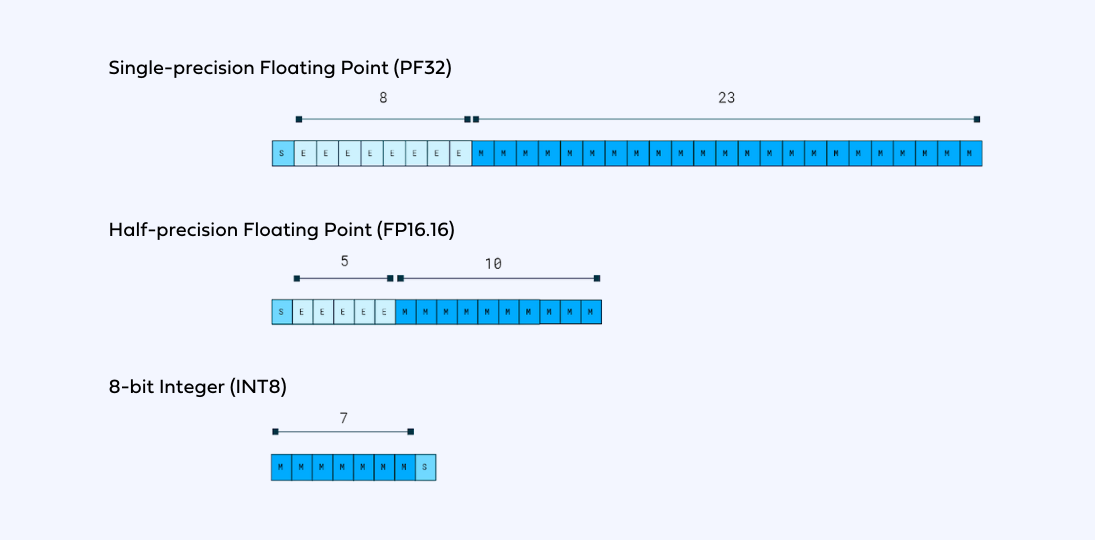 {:height 362, :width 719}
{:height 362, :width 719}
Quantization to Int8
Let’s consider a float x in [a, b], then we can write the following quantization scheme, also called the affine quantization scheme:
x = S * (x_q - Z)
x_q is the quantized int8 value associated to x
S is the scale, and is a positive float32
Z is called the zero-point, it is the int8 value corresponding to the value 0 in the float32 realm.
x_q = round(x/S + Z)
x_q = clip(round(x/S + Z), round(a/S + Z), round(b/S + Z))
In effect, this means that we clip the ends, and perform a scaling computation in the middle. The clip-off obviously will lose to accuracy of information, and so will the rounding.
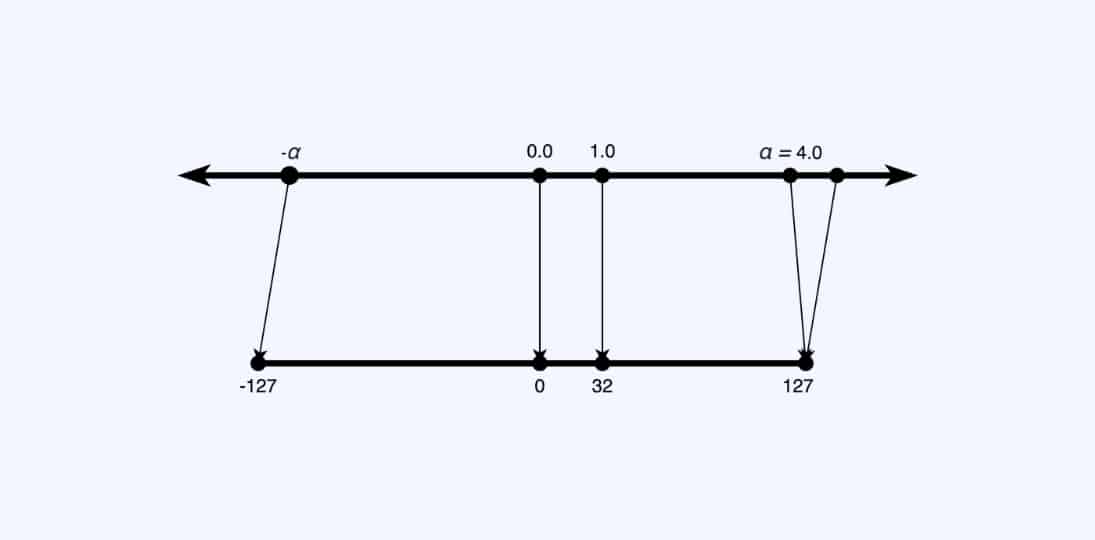
Calibration
An example, explaining calibration to optimise clipping vs rounding error
 {:height 187, :width 314}
{:height 187, :width 314}
To ensure that we have a good balance of clipping vs rounding errors, based on the range [a, b] that we select. Some techniques are available
Use per-channel granularity for weights and per-tensor for activations
Quantize residual connections separately by replacing blocks
Identify sensitive layers and skip them from quantization
https://huggingface.co/blog/4bit-transformers-bitsandbytes
Model quantization + instruct = Quite Good results
Good reference reading on the topic: https://deci.ai/quantization-and-quantization-aware-training
What’s next
This post was more around understanding some fundamental concepts, I’ll not take this learning for a spin and try out deepseek-coder model. I’m primarily interested on its coding capabilities, and what can be done to improve it.
Part-2 of this post is available here