Introduction
The goal of this series of posts, is to form foundational knowledge that helps us understanding modern state-of-the-art LLM models, and gain a comprehensive understanding of GPT via reading the seminal papers themselves.
In my previous post, I covered some of the seminal papers that formulated sequence based models from RNNs to the Attention mechanism in encoder-decoder architectures. If you don’t know about them, or would like a quick refresher - I recommend reading through the previous post before continuing here.
This post will focus on the “Attention is all you need” paper that introduced the ground-breaking transformer architecture to the world and has since started a cascading and exponential affect on the AI landscape.
Papers to be covered in this series
[THIS POST] Transformers, following Vaswani et al. 2017 Google Attention is all you need
GPT-1, following Radford et al. 2018 Improving Language Understanding by Generative Pre-Training
GPT-2, following Radford et al. 2018 Language Models are Unsupervised Multitask Learners
BERT, following Devlin et.al. 2019 Google Pre-training of Deep Bidirectional Transformers for Language Understanding
RoBERTa, following Liu et. al. A Robustly Optimized BERT Pretraining Approach
GPT-3: Few shot learners, 2020 OpenAI Language Models are Few-Shot Learners
PaLM: following Chowdhery et al. 2022 Scaling Language Modeling with Pathways
Maybe: MACAW-LLM, following Lyu et al. 2023 MULTI-MODAL LANGUAGE MODELING
Transformers
Paper
Transformers, following Vaswani et al. 2017 Google Attention is all you need
The problem its solving
This inherently sequential nature (of RNNs) precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples
Intention
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output.
Architecture
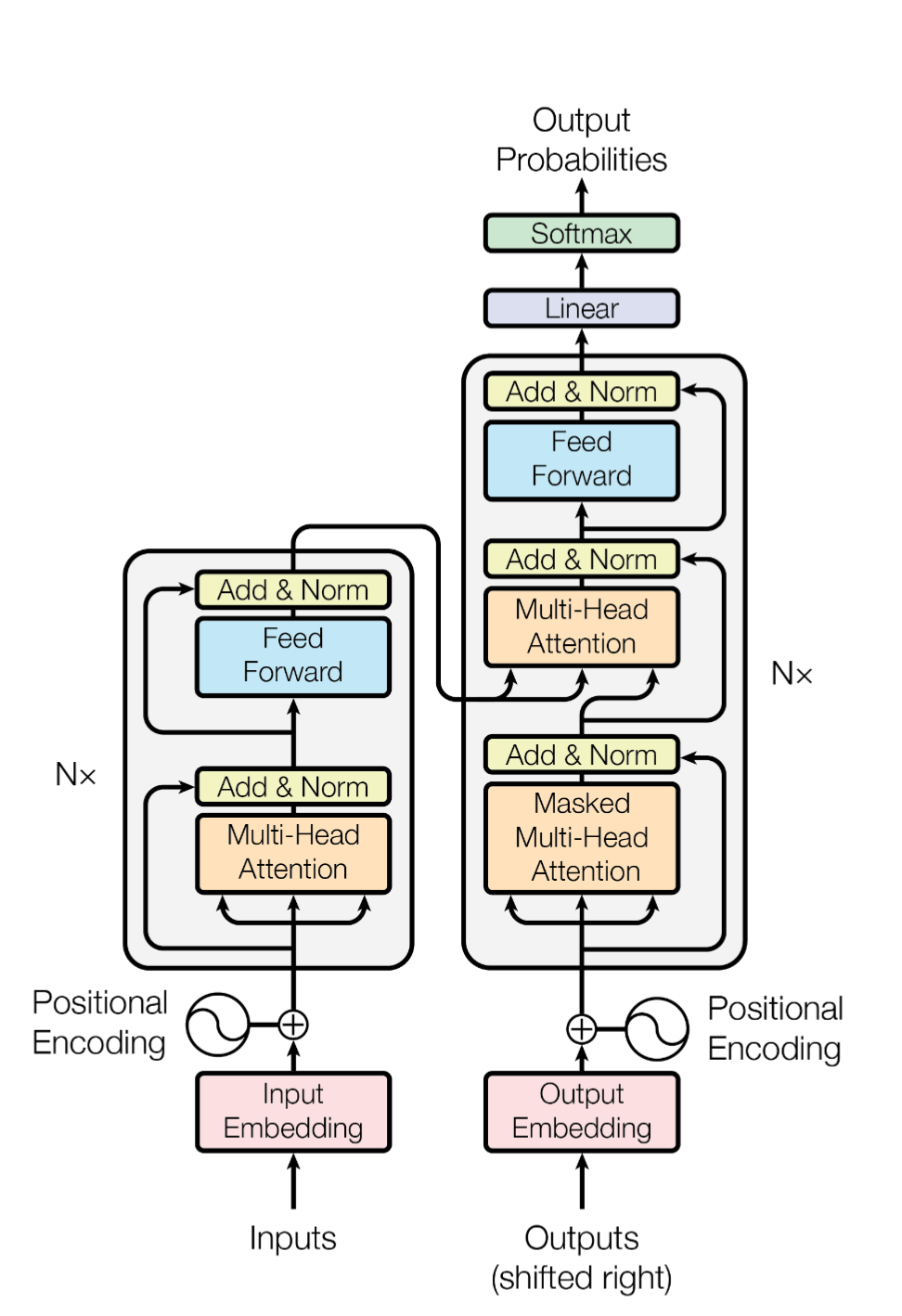
Main Points
Attention
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
- Its helpful to see the additive attention that was described previously in the paper by Dzmitry
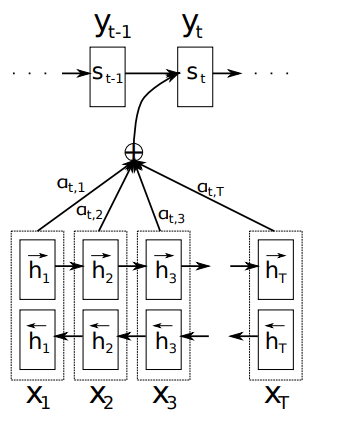
Refer to the diagram above from the paper by Dzmitry . In it, attention is realised by creating a context vector C that is generated via an alignment model. The model has weights alpha[tx,ty] that act as weighted sum on the states h[j] of the encoded sentence. This helps provide an “attention” mechanism.
I believe the authors are summarising this behaviour by explaining attention as a query + key-value pairs => output.
The query in this case, is the alpha vector that understands which parts of the X[t] to query. The values are the hidden-states h[j], and the keys are the time/positions that relate to that value h.
In affect, the attention mechanism is a way for the decoder network to query the positionally encoded hidden states, based on the current state s[t-1]
Later in the paper, they also mention the following:- In “encoder-decoder attention” layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence. This mimics the typical encoder-decoder attention mechanisms in sequence-to-sequence models
But note that the previous paper relies on an RNN to create the context of time, which the current papers want to get rid of. So how do we create the keys then?
Another helpful visualisation of attention, is found in the paper Massive Exploration of Neural Machine Translation Architectures
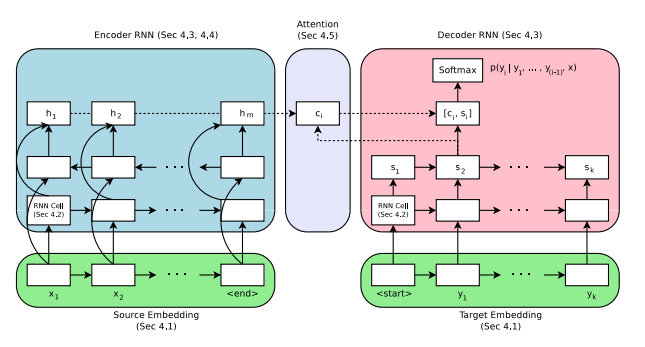
Scaled Dot-Product Attention
The authors hint that they prefers the multiplicative attention mechanism, due to its computational effeciencies - even though historically the additive attention has proven to work better.
Additive vs Multiplicative Attention
While the transformers paper doesn’t explain the difference between the additive and multiplicative versions. The referenced paper can be expanded to understand them.
Equation 6 is the additive version, and 7 is the multiplicative version
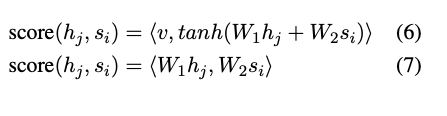
The multiplicative attention is introduced here by Luong et al.
The authors hypothize that the multiplicative attention has underperformed as it moves the logits into extreme ends where the gradients are close to 0. So they choose to scale down the logits before passing them to the softmax.
We compute the dot products of the query with all keys, divide each by √dk, and apply a softmax function to obtain the weights on the values
Mathematically
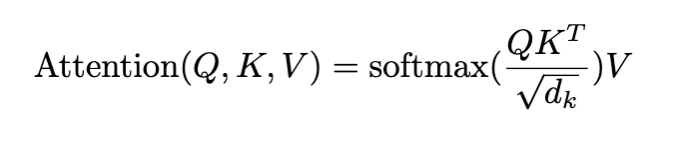
- This is similar to doing the weighted sum on the values, where the weights are a softmax outputs from aligning the queries and the keys via a dot-product
Visually
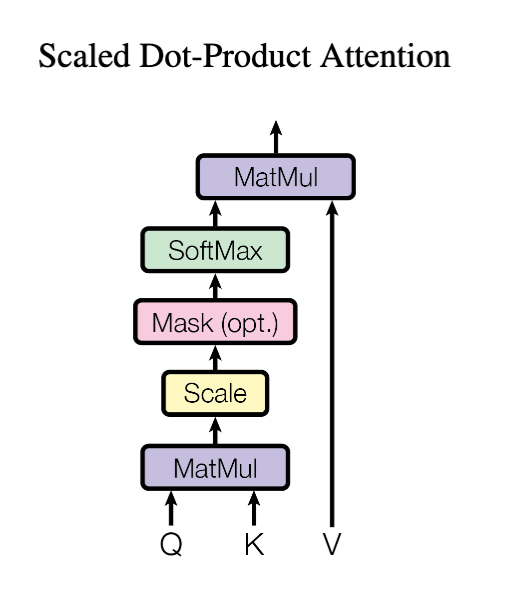
Multi-Head Attention
Further, the authors propose to do multi-head attention. This is essentially a way to parallelise the attention process on multiple heads instead of a single head.
So instead of doing a single attention with d_model dimensions. They, parallely run N attention models with d_model/N dimensions each.
The reason for doing this?
Multi-head attention allows the model to jointly attend to information from different representation
subspaces at different positions. With a single attention head, averaging inhibits this.
Mathematically:

Self Attention
Self attention, is essentially where the attention is given to itself, rather than a separate encoder model.
They use this in the encoder. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
Positional Encoding
Since the authors completely got rid of the recurrence, or convolutional parts in the network - they need to provide the model with the positional information to compensate for this missing and crucial context.
To that effect, they chose to create positional embeddings (with the same dim size as the text embeddings).
But, they chose to not make them learnable parameters - and that makes sense to me.
They create the positional embeddings with the following logic
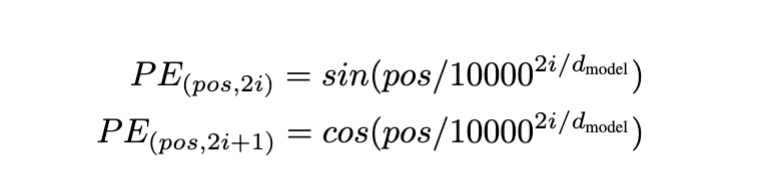
We
chose this function because we hypothesized it would allow the model to easily learn to attend by
relative positions, since for any fixed offset k, P Epos+k can be represented as a linear function of
P Epos.
The d2l.ai book has the best explanation to this that I could find.
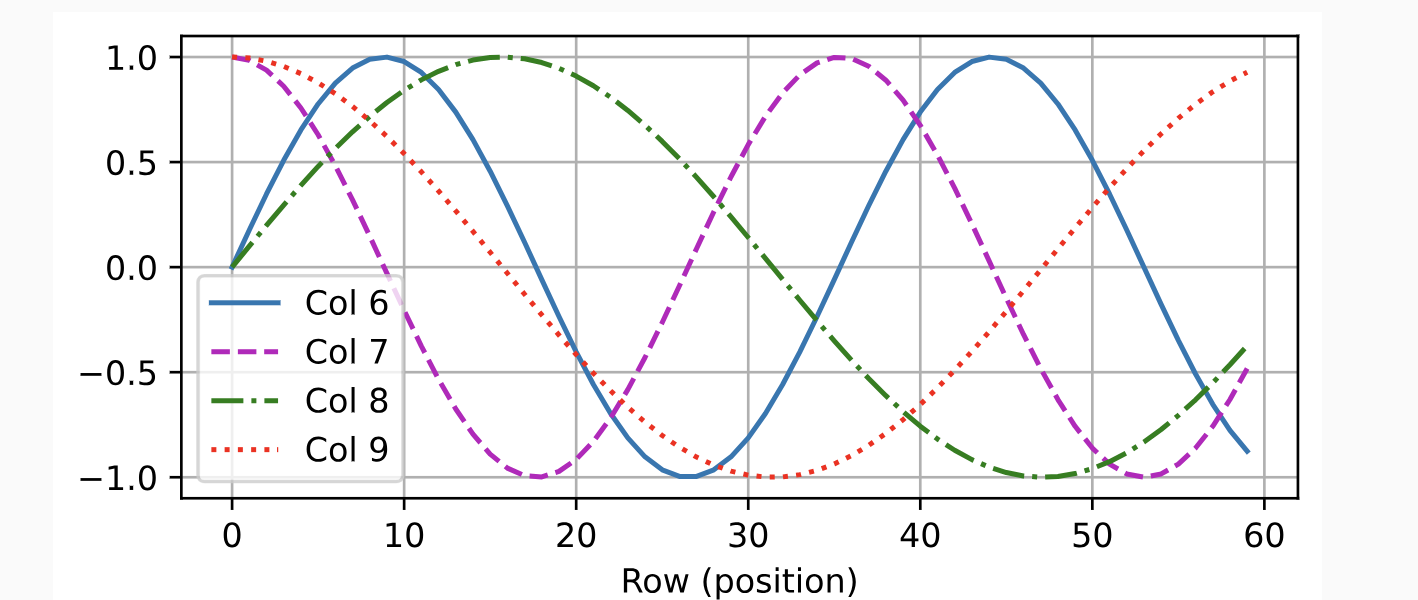
If we plot different columns, we can see that one can easily be transformed into the other, via linear transformations.
Even after this though, I don’t think I fully understand this part well. For now, I’ve marked this as a TODO, and will come back to it later.
Why Self-Attention
The core of this goes back to the original intention described towards the beginning of the paper.
As a reminder
This inherently sequential nature (of RNNs) precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples
The authors detail this by comparing the complexity of different layers, and also how traversing the path for finding long-range dependencies is easy with attention, but relatively complex in other forms.
Below is the tabular version for comparison

Few key points
Comparison with convolutions
- In convolutions, long range dependencies would require a stack of N/k convolutional layers. Traversing such a path, hence takes Log_k(n). They are generally more expensive then recurrent layers by a factor of k in terms of complexity
Comparison with recurrence
- The core win here, is that recurrent connections require n sequential operations, which becomes O(1) with self attention
Attention is also more interpretable
- The authors are able to build attention distributions on the model, to realise that the model is relatively easier to reason about the relationship between positions and tokens.
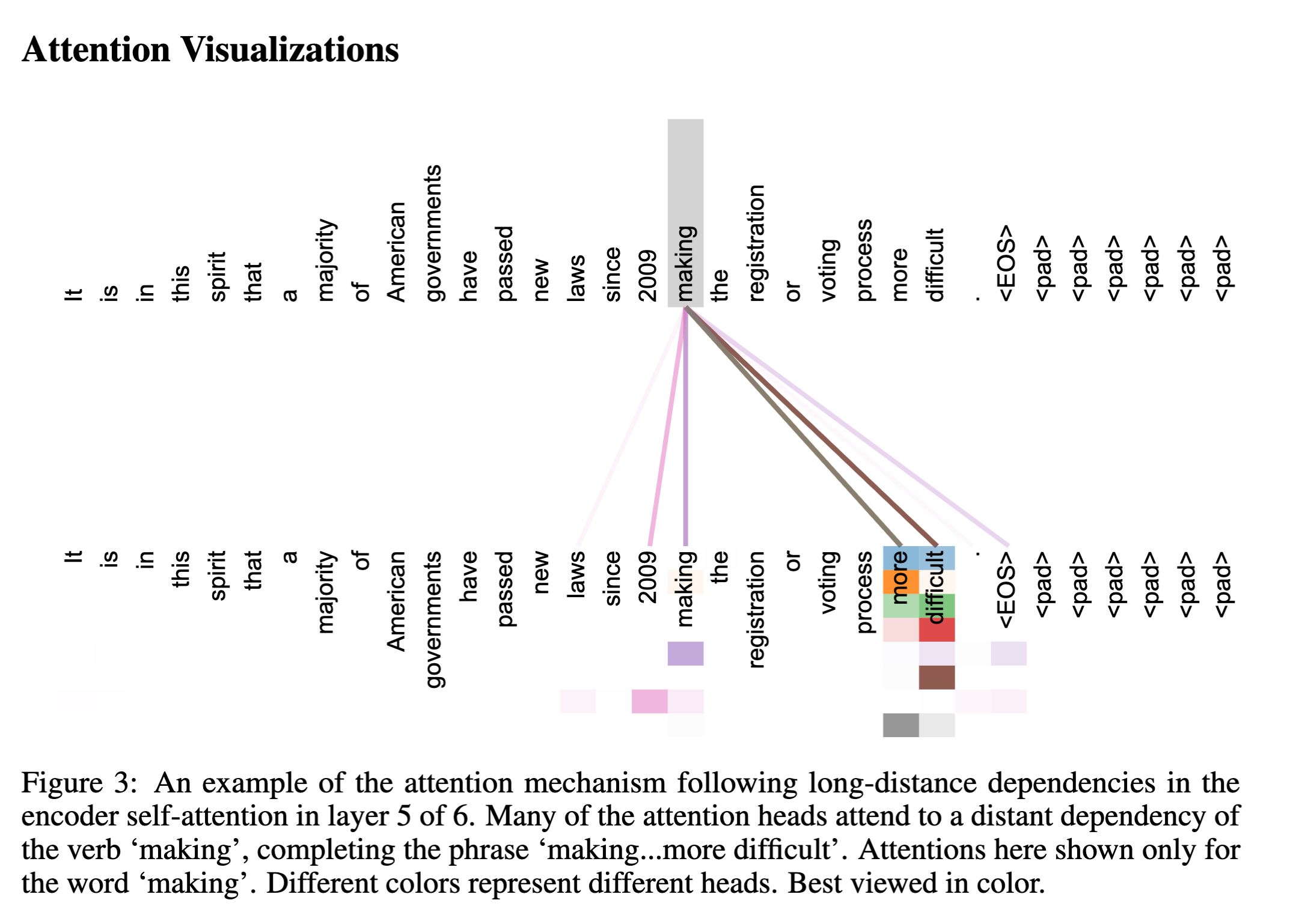
Conclusion
The paper packs a ton of things into it. Its brilliant, but also probably takes a few iterations to absorb all the content well.
I intend to dive into the code that is available in tensor2tensor and update this post with more understanding and learnings from the code.
In the next post, I intend to cover GPT-1 and 2 and work our way towards the GPT-3 and other state-of-the-art model architectures and additions.