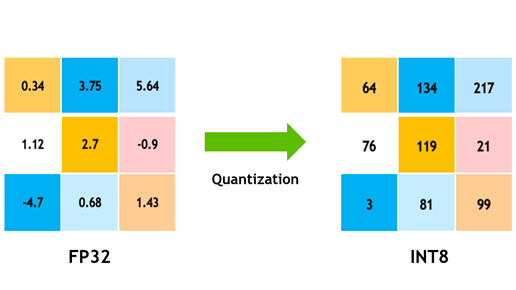
Introduction I previously wrote about writing react code with Deepseek-coder 33b model, and whether we could improve some of these shortcomings with the latest research in the LLM space But to really measure and mark progress, it would require the build of a benchmark to test various hypothesis around it. So in this post, I’m going to evaluate existing benchmarks that specifically measures LLM capabilities on coding capabilities. My goal is to be able to build a benchmark that can test their React/Typescript coding capabilities....